Migrating from Apache/WordPress to relayd/httpd/Hugo
2860 words, 14 minutes
WordPress has served me well since 2010. But I finally got bored with managing the OAMP stack and having to deal with plugins updates, spam comments and general security warning because of the PHP backend.
After reading a lot and testing a few Static Site Generator, I decided to go with Hugo to expose all my HTML stuff. And as PHP is not required anymore, I also decided to replace Apache with OpenBSD’s httpd(8) and relayd(8).
Exporting the content out of WordPress
Something most of us will not think of when it comes to storing data is Reversibility ; that is the possibility / difficulty to get back our data from where we stored them.
One of the nice WordPress’ feature is that it:
- provides the possibility to be self-hosted ;
- stores data in HTML format inside a MySQL database.
Those makes it possible to, at least, get a bunch of HTML data out of MySQL once you decide to get out of WordPress. But there are also WordPress plugins that allow you to export your data into some other format. And in my particular case, in Markdown.
Preparing PHP
There is a plugin that allows export automation. WordPress to Hugo Exporter will run on your WordPress instance, browse the whole media database and export everything into an archive file. This archive will be filed with your media (images, files, …) and a conversion of the WordPress articles and pages into MarkDown.
While using it the first times, I faced various issues. All of them were due to PHP configuration being too restrictive (or secured) when it comes to running scripts and deal with data upload/download.
I was using Apache and php-fpm. And those were the kind of errors I encountered:
AH01071: Got error 'PHP message: PHP Fatal error: \
Maximum execution time of 30 seconds exceeded in (...)hugo-export.php \
on line 428'
The timeout specified has expired: \
AH01075: Error dispatching request to : (polling)
AH01071: Got error 'PHP message: PHP Fatal error: \
Allowed memory size of 268435456 bytes exhausted \
(tried to allocate 609181696 bytes) in (...)hugo-export.php on line 462'
To have the export working, some modifications were required in Apache Reverse-Proxy configuration and PHP limits.
# vi /etc/php-7.4.ini
(...)
max_execution_time = 300
(...)
memory_limit = 512M
# /etc/rc.d/php74_fpm restart
# vi /etc/apache/httpd.net
(...)
<IfModule proxy_fcgi_module>
TimeOut 300
ProxyTimeout 300
<FilesMatch "\.php$">
SetHandler "proxy:fcgi://127.0.0.1:9000"
</FilesMatch>
</IfModule>
# rcctl restart apache2
While you’re there, verify that the ZIP PHP extension is installed and enabled.
Installing and running the plugin
While logged in using a shell, move to the WordPress plugin directory, download the WP2Hugo plugin and install it:
# cd /var/www/htdocs/wp-content/plugins
# ftp https://github.com/SchumacherFM/wordpress-to-hugo-exporter/archive/master.zip
# unzip master.zip
You can now log into the WordPress Web interface and activate the
plugin. When done, browse to the Tools section and run Export to Hugo.
Within a few seconds/minutes, the Web browser should start downloading
a hugo-export.zip file. Mine was 173MB thick. Store that archive on
the computer you will run Hugo later on.
Cleaning and Transfert
Once the WordPress to Hugo export is finished, you should probably roll-back the changes you made on Apache & PHP configuration.
Setup the Hugo environment
I decided that I wouldn’t be running the Hugo infrastructure on the same server as the one which will be publishing the Web content. First, this makes the Web server lighter. Secondly, this will provide an easy way to have a staging environment.
The Hugo environment lies on my laptop. I can locally test everything before rsyncing the HTML static resources to the Web server.
Install Hugo
On OpenBSD, Hugo is available as a binary package.
# pkg_add hugo
Your choice: 2
hugo-0.88.1-extended:libsass-3.6.5v0: ok
hugo-0.88.1-extended: ok
Read shared items: ok
Setup initial directory
You need a root directory for your Hugo website. So create a directory and declare it as a new Hugo site.
# mkdir ~/tumfatig
# cd ~/tumfatig
# hugo new site .
Congratulations! Your new Hugo site is created in /home/jca/tumfatig.
Just a few more steps and you're ready to go:
1. Download a theme into the same-named folder.
Choose a theme from https://themes.gohugo.io/ or
create your own with the "hugo new theme <THEMENAME>" command.
2. Perhaps you want to add some content. You can add single files
with "hugo new <SECTIONNAME>/<FILENAME>.<FORMAT>".
3. Start the built-in live server via "hugo server".
Visit https://gohugo.io/ for quickstart guide and full documentation.
Take the time to read the quickstart guide. It’s really worth it.
The Hugo website is now created ; but it is empty. And it has the a default look.
Customization
The Hugo configuration file is config.toml. It is possible to use a
config.yaml or config.json file. But I used the one that was
generated at the “new site” step.
The following tells Hugo what the Web site name is and where to install the rendered files. This will have an action on the generated links.
baseURL = "https://www.tumfatig.net/"
publishDir = "/var/www/htdocs/hugo"
A robot file can be created or copied from the
themes/<Your Theme>/layouts/robots.txt using the enableRobotsTXT = true parameter.
Hugo can also produce various outputs of the site. The following:
[outputs]
home = ["HTML", "JSON", "RSS"]
tells Hugo to produce JSON and RSS resources in addition to the HTML ones. The JSON output can be later on used to provide some search feature. The RSS output will allow readers to get notify of new contents using an RSS reader.
The permalinks option tells Hugo to generate “pretty” urls. I replaced
my previous WordPress setting with a simpler / shorter one.
[permalinks]
posts = "/:year/:title/"
Theming
There are loads of available Hugo theme. And they are easy to install.
# cd themes
# git clone https://github.com/vimux/mainroad
# cd ..
# vi config.toml
(...)
theme = "mainroad"
This enables the mainroad theme for the Hugo site.
I was not intirely satisfied with the themes I found. I liked anubis,
even, fuji, mainroad and minimal. But I wanted some kind of a
mix. So thanks to the great Creating a Hugo Theme From
Scratch
article, I ended up building my own.
It’s not that easy. But it’s a great opportunity to learn or update your knowledge on HTML/CSS/… And it also helps understanding how Hugo organizes and renders stuff.
I also wrote my own shortcuts to render the images gallery the way I wanted, without having to use heavy JS libraries.
Install old exported data
I first tried to simply extract the hugo-export.zip content
inside the Hugo directory tree. But this lead to a messy mixed of files
that didn’t really comply with what I understood from the Hugo docs.
So I simply extracted the archive inside the content directory. That
created a hugo-export directory with all the converted WordPress
stuff. And I picked up each article, one by one, corrected it and placed
any required resources (like images etc) in the proper Hugo location.
Edit/Review/Rename old data
Reviewing the old articles content, correcting conversion errors & such took a whole lot of time. Identifying converted URL for external links, internal links and image gallery also was a pain the *ss to correct. I believe 10 years of WordPress upgrades is mostly what turned my “proper” HTML content into a big mess of plain text, HTML tags and elements.
Here’s a few commands I could run to automate the content correction:
find ./ -type f -name "*.md" -exec sed -i -E "s/\&\#8211\;/-/g" {} \;
find ./ -type f -name "*.md" -exec sed -i -E "s/\&\#8216\;/'/g" {} \;
find ./ -type f -name "*.md" -exec sed -i -E "s/\&\#8217\;/'/g" {} \;
find ./ -type f -name "*.md" -exec sed -i -E "s/\&\#8242\;/'/g" {} \;
find ./ -type f -name "*.md" -exec sed -i -E "s/“/\"/g" {} \;
find ./ -type f -name "*.md" -exec sed -i -E "s/”/\"/g" {} \;
find ./ -type f -name "*.md" -exec sed -i -E "s/…/.../g" {} \;
find ./ -type f -name "*.md" -exec sed -i -E "s/\<\;/</g" {} \;
find ./ -type f -name "*.md" -exec sed -i -E "s/\>\;/>/g" {} \;
find ./ -type f -name "*.md" -exec sed -i -E "s/\ \;/ /g" {} \;
find ./ -type f -name "*.md" -exec sed -i -E "s;^> <pre>;\`\`\`;" {} \;
I also got help from vim(1) to convert some remaining dirt:
:%s/^> //
:%s/```$/\r```/
:%s/^```/```\r/
:%s;^<pre>;```\r;
:%s/ //g
:%s;^```<p>;```;
:%s;^</p>```;```;
There were loads of HTML encoded characters. There were misplaced ‘code’ tags, remaining ‘p’ tags, backslashed underscore characters, …
There also were lots of URL pointing to WordPress CDN rather than local resources and/or using short WP urls. Those had to be corrected too.
Gallery and images rendering was also not properly translated. There was the complete lightbox/jquery/… HTML code written in the markdown. Those were totally unuseable and also made the whole MD file not renderable.
In the end, all my stuff was cleaned and organized this way:
[Hugo root directory]
|- config.toml
|- assets/
| |- images/
| |- 2010/
| |- 2011/
| |- (...)
| |- 2021/
|- content/
| |- about/index.md
| |- disclaimer/index.md
| |- (...)
| |- posts/
| |- 2008
| |- (...)
| |- 2021
| |- annotate-your-pdf-files-on-openbsd.md
| |- from-clean-green-mockup-to-openbsd-cwm1-desktop.md
| |- (...)
|- static/
| |- files/
| |- 2010/
| |- 2011/
| |- (...)
| |- 2021/
The images directory contains only pictures. The files directory
contains all the other resources (zip, scripts, text files…). And the
articles are stored by year of publication.
Publishing the static content
There are two ways to access the rendered material. Either use the LiveReload feature or generate the website content to the directory configured earlier.
LiveReload is a feature that provides a built-in web server. The content
is rendered in memory and can be accessed browsing localhost:1313. To
use that feature, simply call hugo server inside the Hugo root directory.
One can use the -D flag to also render the articles marked ad “Draft”.
Deploy Hugo content
Using the hugo command, the website will be rendered and placed in the
location configured in the config.toml file.
I have writen a shell script that can be called with two names:
# cat render
#!/bin/ksh
#
# Render &| Deploy Hugo website
LOCALDIR="/var/www/htdocs"
rm -r $LOCALDIR/*
hugo --cleanDestinationDir --minify
[[ "$(basename $0)" == "deploy" ]] && \
rsync -avz --delete $LOCALDIR/ \
www@webhost:/var/www/htdocs/
exit 0
A file named deploy is a symlink to render. Calling render only
renders the website locally. Calling deploy also replicated the
website to the remote web server.
Using OpenBSD stock daemons
As I said, I also took the decision to drop Apache and use as much stock OpenBSD daemons as possible. I have to use both httpd(8) and relayd(8). Because each one is a specialized tool and has specific features ; not available from the other one. For example, relayd(8) can deal with HTTP headers management whereas httpd(8) can do HTTP redirections.
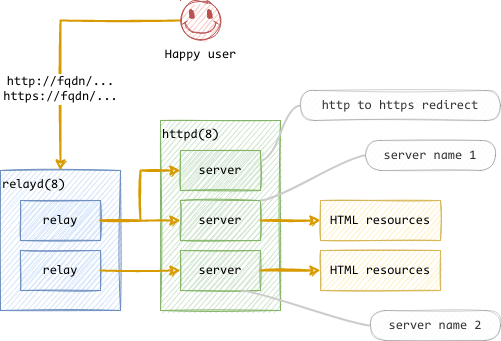
Configure httpd(8)
A generic server is used to deal with acme-challenge and http to https
redirection. It is used by relayd(8) when it detects Let’s Encrypt URL
and when it receives requests using the HTTP protocol. It looks similar
to the one shown in the /etc/examples/httpd.conf file.
A second server is used to deal with the Hugo resources. It defines:
- a specific port on localhost to listen to requests.
- a
log style forwardedso that the log analyser can provide decent information. - a generic rewrite rule that allows URLs to end with “/”. In this case,
the
index.htmlis rendered. If there’s none, an error will be raised. - a heartbeat page used by relayd(8) to be alerted if httpd(8) is down. It is located in another directory.
- an external location that is referenced for HTML pages that are not managed by Hugo ; and lying in another directory.
- an external configuration include dealing with WordPress specifics.
It looks like this:
server "www.tumfatig.net" {
listen on $localhost port 1234
alias "tumfatig.net"
log style forwarded
root "/htdocs/hugo"
location "/" {
request rewrite "/index.html"
}
location "/hb.htm" {
root "/htdocs"
request rewrite "/hb.htm"
}
location "/cws/*" {
root "/htdocs/cws"
request strip 1
directory index index.html
}
include "/etc/httpd.redirect-wordpress.conf"
The WordPress specifics includes:
- Automatic redirection from WP pretty URL to Hugo pretty URL format.
- Automatic redirection from files published in WP to the new Hugo location.
- An error page if you still try to use WP admin pages.
- Automatic redirection for well-known WP url that are now gone.
It looks like this:
location match "^/(%d%d%d%d)%d%d%d%d/(.*)" {
block return 301 "https://$HTTP_HOST/%1/%2"
}
location match "^/wp%-content/uploads/(%d%d%d%d)/%d%d/(.*)" {
block return 301 "https://$HTTP_HOST/files/%1/%2"
}
location match "^/wp%-.*" {
root "/htdocs"
request rewrite "/403.html"
}
location match "^/rss/" {
block return 301 "https://$HTTP_HOST/index.xml"
}
location match "^/tag/(.*)/" {
block return 301 "https://$HTTP_HOST/tags/%1/"
}
That being done, httpd(8) can be enabled and started.
# rcctl enable httpd
# rcctl start httpd
Configure relayd(8)
relayd(8) serves as the public entry spot for all HTTP(S) traffic. It is configured as a reverse-proxy regarding the httpd(8) servers. It is using the Relays and Protocols features.
Redirect HTTP to HTTPS
relayd(8) does not have (yet) the ability to detect plain HTTP and ask
the browser to switch to HTTPS. This is done by httpd(8). So I’m using a
simple http protocol, that will add X-Forwarded- headers to request
and pass it to the httpd(8) “HTTP to HTTPS” server configuration.
# vi /etc/relayd.conf
(...)
table <httpd> { 127.0.0.1 }
(...)
http protocol "http" {
match request header append "X-Forwarded-For" value "$REMOTE_ADDR"
match request header append "X-Forwarded-By" \
value "$SERVER_ADDR:$SERVER_PORT"
(...)
}
relay "http" {
listen on $ext_addr port 80
protocol "http"
forward to <httpd> port 8080 check http "/hb.htm" code 200
}
Publishing HTTPS content
I defined a more complex http protocol to deal with HTTPS traffic and
apply “routing” rules and HTTP headers modification:
- Adding
X-Forwarded-HTTP headers. - Adding “security” and “privacy” HTTP headers.
- Checking for
HostHTTP header and only accept a limited number of them. Unacceptable value are forwarded to a specific httpd(8) server and HTML message. - Checking for specific objects and set a
Cache-Controlvalue on them.
Those rules map into the following configuration:
# vi /etc/relayd.conf
(...)
table <httpd> { 127.0.0.1 }
table <website1> { 127.0.0.1 }
table <website2> { 127.0.0.1 }
table <forbidden> { 127.0.0.1 }
(...)
http protocol "https" {
match request header append "X-Forwarded-For" value "$REMOTE_ADDR"
match request header append "X-Forwarded-By" \
value "$SERVER_ADDR:$SERVER_PORT"
(...)
match response header set "Permissions-Policy" \
value "camera=(), microphone=()"
match response header set "Referrer-Policy" \
value "no-referrer"
match response header set "X-Content-Type-Options" \
value "nosniff"
match response header set "X-Download-Options" \
value "noopen"
match response header set "X-Frame-Options" \
value "SAMEORIGIN"
match response header set "X-Permitted-Cross-Domain-Policies" \
value "none"
match response header set "X-Robots-Tag" \
value "none"
match response header set "X-XSS-Protection" \
value "1; mode=block"
match response header set "Strict-Transport-Security" \
value "max-age=15552000; includeSubDomains; preload"
(...)
match request tag "forbidden"
match request header "Host" value "www.website1.com" tag "website1"
match request header "Host" value "www.website2.com" tag "website2"
pass request tagged "website1" forward to <website1>
pass request tagged "website2" forward to <website2>
pass request tagged "forbidden" forward to <forbidden>
(...)
match request path "/*.css" tag "caching"
match request path "/*.jpg" tag "caching"
match request path "/*.png" tag "caching"
match request path "/*.woff2" tag "caching"
match response tagged "caching" header set "Cache-Control" \
value "public, max-age=86400"
(...)
A dedicated relay is then configured using this protocol and forwards the HTTPS traffic to the proper httpd(8) servers:
relay "https" {
listen on $ext_addr port 443 tls
protocol "https"
forward to <website1> port 8081 check http "/hb.htm" code 200
forward to <website2> port 8082 check http "/hb.htm" code 200
forward to <forbidden> port 8666 check http "/hb.htm" code 200
}
That being configured, relayd(8) can now be started automatically:
# rcctl enable relayd
# rcctl start relayd
General thoughts
I’ve not described how to setup HTTPS and get a TLS certificate using
acme-client(1). This is quite straight forward when following the
manpage instruction and reading the etc/examples/httpd.conf file.
Regarding the replacement of Apache/PHP/MySQL with relayd/httpd, there were quite a few trial & errors before I ended up with a fully working configuration. In the end, the overall configuration is simple to read (and maintain) ; and it uses wayyyyy less RAM and a bit less CPU on my VPS. Those daemons are definitively good choices for such use-case.
One thing a keep an eye on are 404 errors. Although a new sitemap is generated with proper articles links to be registered by bots, there may be “old URL” lying on forums and such. To solve such issues, I look at “yesterday’s log file” and decide if some old URL are worth being set available.
# zgrep " 404 0 " /var/www/logs/access.log.0.gz | awk '{ print $8 }' | \
grep -v "^/wp-[a-z]*/" | sort | uniq -c | sort
I then use the aliases feature of Hugo to configure an HTTP redirection
from the old URL to the new one.
When it comes to the WordPress to Hugo migration, well, it was quite a huge work. All in all, it was not that bad. But be prepared for sweating if your WordPress content is not “simple” and has a big number of articles to convert.